
What is Googlebot and How Does it Work?
by Editor

What is Googlebot
Unveiling the Enigma: How Googlebot Works and What It Means for Your Website
Googlebot, the tireless crawler that powers the vast and intricate landscape of Google Search, is the cornerstone of how websites are discovered, indexed, and ranked.
Understanding how this bot works is essential for anyone looking to improve their website’s search visibility, boost organic traffic, and enhance overall SEO performance.
In this comprehensive guide, we will delve deep into the workings of Googlebot: how it crawls the web, how often it visits your site, what it “sees,” how to optimize for it, and how you can manage and control its access to your pages.
What Is Googlebot, and How Does It Work?
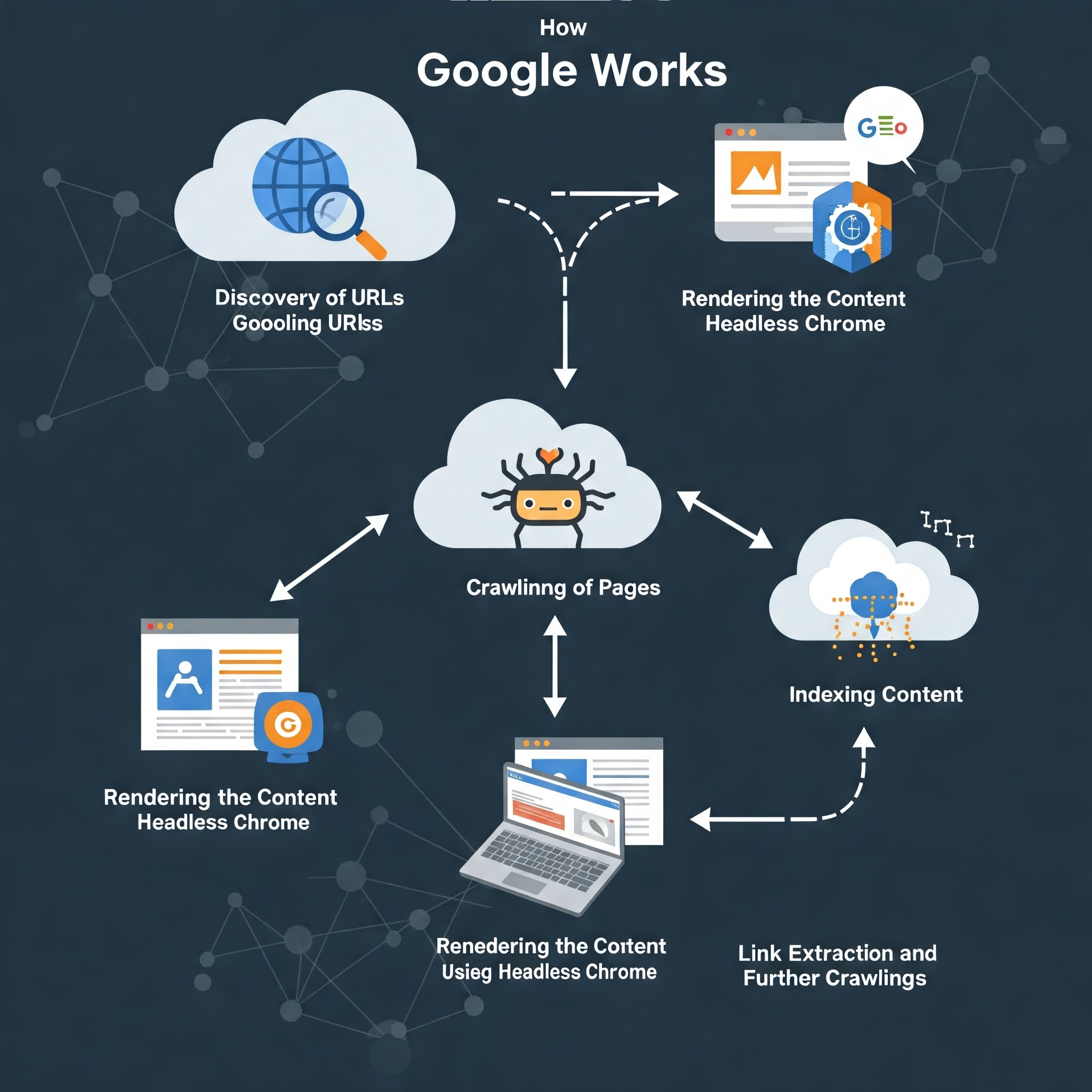
Googlebot is Google’s web crawler, an essential component of the company’s search engine infrastructure.
As the name implies, it “crawls” the internet, systematically following links, gathering information, and adding content to Google’s search index.
While Googlebot is often thought of as one single entity, it is, in fact, a suite of crawlers that includes specialized bots designed for different tasks.
For example, Googlebot Smartphone crawls pages optimized for mobile, Googlebot Desktop focuses on desktop content, and Googlebot Image handles image-based content.
The goal of Googlebot is to gather web content and make it available for indexing so that it can be used to respond to user queries.
Googlebot works tirelessly to maintain an up-to-date database of the web, ensuring that new pages and updated content are available to searchers.
Here’s an overview of how Googlebot operates:
1. Discovery of URLs
The process starts with Googlebot receiving a list of URLs, known as the “crawl queue,” from various sources.
These include sitemaps submitted by website owners, links found on other indexed pages, external websites linking to your content, or previously crawled pages.
Googlebot doesn’t just start at the homepage and then crawl down; instead, it follows the links on each page it visits to discover additional URLs. This means that as new links are discovered, the crawl queue continuously expands.
2. Requesting and Crawling Pages
Once Googlebot identifies a URL, it sends a request to the server hosting that page. The server responds with a collection of resources: HTML content, JavaScript files, CSS stylesheets, images, and more. Googlebot fetches these resources in preparation for analyzing the content.
3. Rendering and Understanding Content
After fetching a page’s resources, Googlebot uses a headless Chrome browser to render the content. This step is essential for understanding how a user would view and interact with the page.
Googlebot needs to parse not only the HTML but also how it’s styled and how any dynamic content is displayed using JavaScript.
This is particularly important for websites that rely on JavaScript for rendering content, such as Single Page Applications (SPAs) or content that loads dynamically after the page is loaded.
4. Indexing the Content
Once the page has been rendered, Googlebot analyzes the content it sees—looking at text, images, metadata, links, and other key elements.
This information is then added to Google’s index, a massive database of all the content that Googlebot has crawled.
The indexing process allows Google’s search engine to rank the page based on relevance when users search for related terms.
5. Link Extraction and Further Crawling
One of the primary functions of Googlebot is to follow links. As Googlebot crawls and renders a page, it extracts links to other pages on your website (or external sites) and adds them to the crawl queue.
This cycle of following links and discovering new pages is what allows Googlebot to map out and index the entire web over time.
How Often Does Googlebot Crawl?
The frequency with which Googlebot crawls your website depends on several factors, some of which you can influence, and others that are controlled by Google’s algorithms.
Understanding these factors can help you ensure that Googlebot visits your site more frequently, leading to faster updates in Google’s index and ultimately improving your site’s search engine rankings.
1. Website Popularity
Highly authoritative or popular websites tend to be crawled more often. This is because they receive more traffic, have more backlinks, and are more likely to have frequently updated content.
Googlebot prioritizes pages that are frequently updated or have new, valuable content to ensure that the search index remains up to date.
2. Content Update Frequency
Websites that are regularly updated or add new content (like blog posts, news articles, or product pages) are crawled more frequently. Googlebot prioritizes sites that frequently change because they offer fresh content that can be useful for searchers.
3. Website Size
Larger websites with hundreds or thousands of pages tend to be crawled more frequently because Googlebot must ensure that all pages are indexed.
However, for such websites, Googlebot may crawl only a subset of pages during each visit, depending on the site’s crawl budget.
4. Backlink Profile
Pages with more backlinks are considered more authoritative, and as a result, they tend to be crawled more often. High-quality backlinks signal to Googlebot that the page is relevant and valuable, making it more likely to be revisited regularly.
5. Crawl Budget
Every website has an allocated “crawl budget,” which is the number of pages Googlebot will crawl within a given time frame.
The crawl budget depends on several factors, such as the size of the website, its performance, and its popularity.
Websites that perform well, with fast loading times and minimal server errors, are allocated higher crawl budgets.
Although you can’t control the exact crawl frequency, you can influence how often Googlebot revisits your pages by consistently publishing high-quality content, building an authoritative backlink profile, and improving the overall user experience on your website.
Optimizing Your Site for Googlebot Crawlability
While you cannot directly control Googlebot, you can optimize your site to ensure that it’s easy for Googlebot to crawl and index.
This involves a combination of technical improvements, content strategies, and site structure enhancements that make it easier for Googlebot to do its job effectively.
1. Create a Sitemap
An XML sitemap is a file that lists all the important pages on your website, helping Googlebot discover and index them more efficiently.
You can submit your sitemap to Google via the Google Search Console to ensure that it’s being accessed regularly. Having a sitemap is especially important for larger websites or websites with complex structures.
2. Improve Site Speed
Site speed is a critical factor for both user experience and crawl efficiency. Googlebot tends to prioritize fast-loading websites because they provide a better experience for users and are easier to crawl. To improve your site’s speed, you can:
- Compress images to reduce load times.
- Minify CSS and JavaScript files.
- Use a Content Delivery Network (CDN) to distribute content across multiple servers.
- Optimize server response time to reduce delays.
3. Ensure Mobile-Friendliness
Mobile-first indexing means that Googlebot uses the mobile version of your site for crawling and indexing, so it’s essential to have a responsive design that provides a seamless experience across devices.
This also means that any content or functionality that’s hidden or inaccessible on mobile may not be indexed correctly. Test your site’s mobile-friendliness using Google’s Mobile-Friendly Test tool.
4. Improve Internal Linking
Internal linking helps Googlebot discover all the pages on your site. By linking relevant pages to one another, you allow Googlebot to navigate your website more efficiently.
Use descriptive, keyword-rich anchor text for your internal links to provide additional context to the bot about the content on the linked page.
5. Ensure a Clear Site Structure
A well-organized website is not only user-friendly but also helps Googlebot understand the relationship between different pages.
Implement a hierarchical structure with clear categories, subcategories, and URLs that make sense. This will help Googlebot crawl your site more efficiently and better understand the context of each page.
6. Fix Broken Links
Broken links, both internal and external, create barriers for Googlebot and can cause the bot to miss important pages on your site. Use tools like Screaming Frog or Google Search Console to find and fix broken links regularly.
7. Secure Your Site with HTTPS
Googlebot gives preference to secure websites. Using HTTPS encryption protects your users’ data and helps build trust. If your site is still using HTTP, it’s time to switch to HTTPS to improve security and boost SEO rankings.
How to See What Googlebot Sees: Using the URL Inspection Tool
Google Search Console offers the URL Inspection Tool, which allows you to see exactly what Googlebot sees when it visits your page. This tool gives you valuable insights into how Googlebot renders and indexes your content.
Here’s what the URL Inspection Tool lets you do:
- See the rendered HTML of your page, which includes dynamic content generated by JavaScript.
- Check if your page is mobile-friendly and accessible to users on all devices.
- Identify crawling or indexing issues that might prevent Googlebot from accessing or indexing your content.
- See the resources that Googlebot has been able to load, including images, scripts, and stylesheets.
- Inspect JavaScript outputs to ensure that dynamic content is visible to Googlebot.
By using this tool, you can identify potential issues and fix them to improve your site’s crawlability and indexation.
How to Control Googlebot’s Access via Robots.txt
The robots.txt file is a powerful tool that gives you the ability to control which pages Googlebot and other crawlers are allowed to access.
This file is placed in the root directory of your website and provides directives to search engine bots about which pages to crawl and which to avoid.
1. Allow Googlebot to Crawl All Content
If you want Googlebot to crawl and index all pages on your website, your robots.txt file should look like this:
User-agent: Googlebot
Allow: /
User-agent: Googlebot-Image
Allow: /
User-agent: Googlebot-News
Allow: /
This tells Googlebot to access all pages, images, and news content on your site.
2. Block Googlebot from Crawling Certain Pages
If there are certain pages or sections you don’t want Googlebot to crawl, you can use the Disallow directive in your robots.txt file.
For example, if you want to prevent Googlebot from accessing the /private/ directory, use the following code:
User-agent: Googlebot
Disallow: /private/
To block all crawlers from accessing your site entirely, you can use:
User-agent: *
Disallow: /
However, be cautious with this, as it can limit your site’s visibility in search results.
Preventing Indexing of Specific Pages Using Meta Tags
While the robots.txt file helps control crawling, it does not prevent pages from being indexed. To stop a page from appearing in search results, you should use the noindex meta tag in the page’s HTML <head> section.
<meta name="robots" content="noindex">
This tag instructs Googlebot not to index the page, even if it is crawled. It’s particularly useful for blocking duplicate content or low-value pages that you don’t want to appear in search results.
Final Thoughts
Googlebot plays a crucial role in how Google indexes and ranks web content. By understanding how it works, you can optimize your website to improve crawlability, speed up indexing, and boost your search rankings.
By focusing on technical SEO aspects like creating XML sitemaps, improving mobile-friendliness, enhancing site speed, and utilizing tools like Google Search Console, you can ensure that Googlebot can efficiently access and index your site.
Additionally, by controlling its access with robots.txt and using meta tags to prevent unnecessary indexing, you can maintain control over what Googlebot sees and prioritizes.
Ultimately, making your site as crawl-friendly and indexable as possible will enhance your chances of ranking well and improving your organic traffic.












